Do Your Judgehosts Scale? 对 ICPC 2023 合肥站评测问题的分析
TOC | 目录
在答应来合肥站帮忙的那天,我怎么都没有想到,赛后自己居然要花好几天时间分析 Linux 内核的问题。
Disclaimer:
- 以下内容均为个人分析的结果;
- 关于 Kernel 的部分可能存在错误,欢迎评论指正。
遇到的问题 tl;dr
因为签到题太简单但测试点又太多,评测队列塞满了。后来删掉了一些测试点之后发现,开始出现很多提交解法没问题,但是被判定超时,并且特征全部都是 judgehost 上报的 Wall time(墙上时钟时间)远高于 CPU time。之后进行了大批量的重测,但是评测非常非常慢,直到蔡队 (@cubercsl) 把 Wall time 上限开到了 10s,评测结果才正确(虽然还是非常非常慢,但是至少能有一份正确的最终榜单)。
「评测机」是一台 2 CPU(CPU 为 Intel(R) Xeon(R) Gold 6133),每个 CPU 20 核心的服务器(包括 Web 服务器在内合计两台服务器,都是从几周前的南京站运过来的),Ubuntu 22.04 + Linux kernel 5.15。最开始开启了 21 个评测实例,后来发现队列阻塞,所以加到了 30 个。故障期间,评测机的 load 为评测实例的两倍,并且有很多 runguard(DOMjudge Judgehost 的评测程序,用于设置隔离等)处于 D 状态。
因为一些巧合,最开始以为是网口/网卡/网卡驱动的问题,但是周一拿到数据库分析之后发现,即使在以为插网线的 hack 之后,问题还是完全没有解决。我找了一台校内的 server,开了一个 32 核心的 KVM 虚拟机(宿主机 CPU 为 Intel(R) Xeon(R) Silver 4314,略差一些),按照文档装上 judgehost 开了 30 个 daemon,ssh -R 12345:localhost:12345 让它能连上我的笔记本的 DOMjudge,然后连着交了 114514 发:
# fish
# 正式比赛中这么做很可能导致你的队伍被 DQ (disqualified)
for i in $(seq 1 114514); ~/Downloads/domjudge-8.2.2/submit/submit --url http://localhost:12345/ --contest hefei -y G.cpp; end
于是惊讶地发现问题可以复现(时间单位为秒):
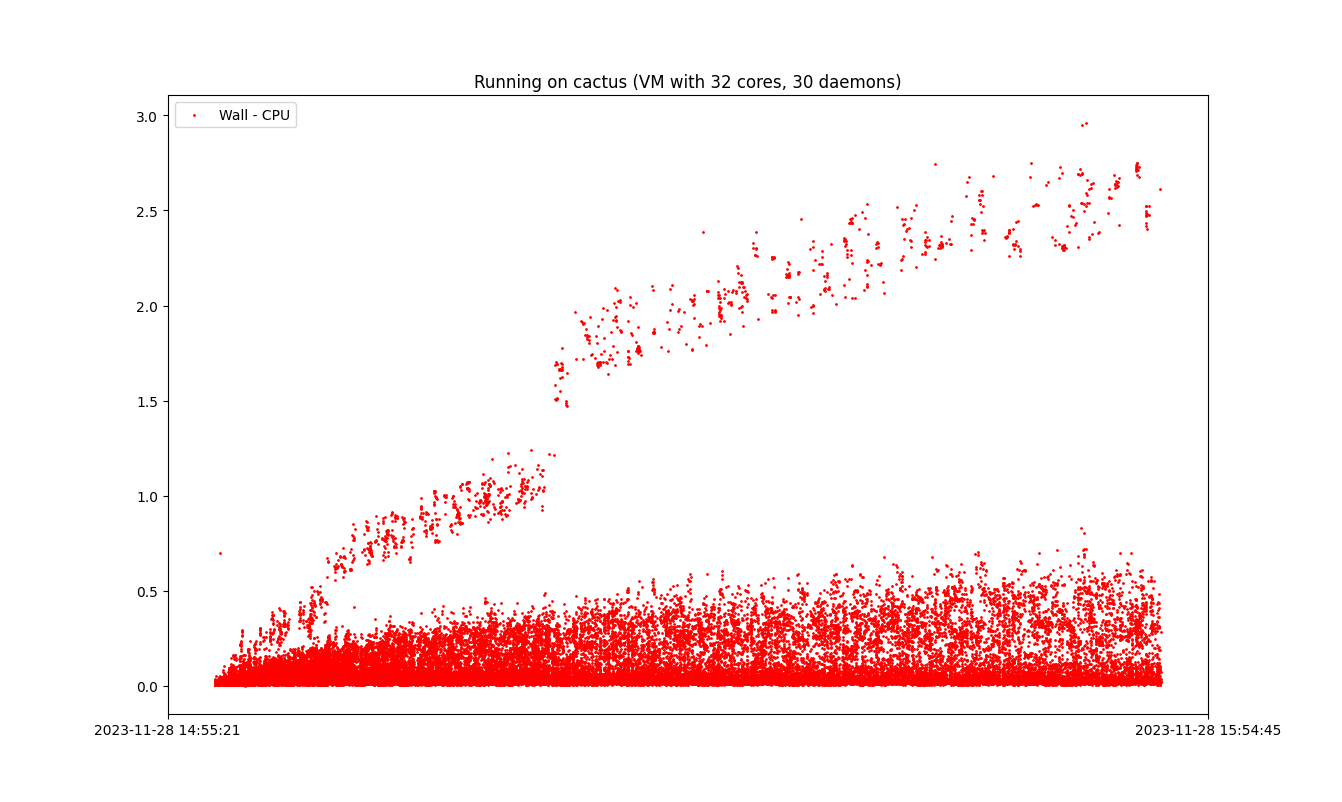
能复现就简单多了,至少不是硬件问题——然后因为提交实在太多了,还好我打了一个数据库的 btrfs 快照,不然我就得重新下数据库打包文件了。
Runguard
Runguard(https://github.com/DOMjudge/domjudge/blob/main/judge/runguard.c)是一个 C 程序,用于设置隔离环境,然后执行选手提交的程序,程序结束之后统计时间、程序输出等信息。它的一些技术选型:
- Chroot 用来隔离文件系统(以及允许我们直接用选手机的 rootfs 来执行程序,一定程度确保一致性)
- Cgroup 用来绑核(cpuset)、限制内存(memory)、统计 CPU 时间(cpuacct)
-
Unshare 用来隔离一些网络之类别的东西:
unshare(CLONE_FILES|CLONE_FS|CLONE_NEWIPC|CLONE_NEWNET|CLONE_NEWNS|CLONE_NEWUTS|CLONE_SYSVSEM);
它的 “Wall time” 是怎么计算的呢:
- 建好 cgroup 之后
fork()。 - 父进程
fork()之后gettimeofday()掐表开始,子进程setrestrictions()之后处理一下标准输入输出错误,然后就 execve。
两者在记时开始之前没有同步,所以 Wall time 是大概率包含 setrestrictions() 的时间的,如果 setrestrictions() 太慢的话,甚至 CPU time 也可能把它算进去。既然选手程序本体没问题,那么问题很可能在 setrestrictions() 上。
在现场 /proc/<pid>/stack 看 D 的 runguard 栈的时候 @iBug 发现很多 runguard 都在 openat/rmdir 里面,以及还有一些 cgroup 相关的东西,那么首先怀疑是 cgroup 的问题。我把 runguard 里面 cgroup 禁用了之后重新编译,再交了 250 发,然后发现:
好了。
尽管没有绑核、没有 CPU time(但是可以直接 user + sys 所以问题不大)、没有内存限制,但是 Wall - CPU 的问题神秘消失了。
之后在开着 runguard cgroup 支持的情况下,我测试了 Ubuntu 22.04 仓库内的 Linux 6.2 内核——问题仍然存在,6.5 OEM 内核——问题消失了。
Bisect
事已至此,只能动手编译内核 bisect 了。花了大半天时间编译了十几份不同版本的内核,最后发现首个解决问题的 commit 是 da27f796a832122ee533c7685438dad1c4e338dd。
ipc,namespace: batch free ipc_namespace structures
Instead of waiting for an RCU grace period between each ipc_namespace
structure that is being freed, wait an RCU grace period for every batch
of ipc_namespace structures.
Thanks to Al Viro for the suggestion of the helper function.
This speeds up the run time of the test case that allocates ipc_namespaces
in a loop from 6 minutes, to a little over 1 second:
real 0m1.192s
user 0m0.038s
sys 0m1.152s
Signed-off-by: Rik van Riel <[email protected]>
Reported-by: Chris Mason <[email protected]>
Tested-by: Giuseppe Scrivano <[email protected]>
Suggested-by: Al Viro <[email protected]>
Signed-off-by: Al Viro <[email protected]>
挺好的,除了看起来和 cgroup 毫无关系以外。但是似乎和 IPC namespace 有关系,联想到 runguard unshare() 给自己搞了个新的 IPC namespace,我把 CLONE_NEWIPC 和 CLONE_SYSVSEM 去掉之后(后者是否有关联不太清楚,但是既然都是 IPC 不如一起删了):
也好了。
所以这个问题:
- Linux 6.3「没问题」,Linux 6.2 以及 5.15 存在;
- 去掉 runguard 里的 cgroup 可以「解决」问题;
- 或者去掉 runguard 里的 IPC namespace 隔离也可以「解决」问题。

我真的很想做这个表情
free_ipc()
看似我们已经获得了解决评测问题的方法,但是原因却还完全没有弄清楚。在 elixir 上翻找一通,以及向 GPT-4 先生请教补习了一些 kernel 知识,然后终于可以解释这个 commit 做了什么了。
(以下代码均以 vanilla 5.15.129 为例)
首先 Linux kernel 有「工作队列」(workqueue) 的机制,允许异步执行一些任务(提交的任务会被对应的 kworker 执行)。free_ipc() 是一个工作任务,从注释看,是因为 RCU 同步的开销比较大,阻塞住不太好:
/*
* The work queue is used to avoid the cost of synchronize_rcu in kern_unmount.
*/
static DECLARE_WORK(free_ipc_work, free_ipc);
其中 RCU 是一种针对读多写少的同步机制,每次同步 synchronize_rcu() 会等待已经开始的 rcu read lock 都 unlock 之后再返回(也被称为 RCU grace period)。
这个工作任务会被 put_ipc_ns() 调度:
/*
* put_ipc_ns - drop a reference to an ipc namespace.
* @ns: the namespace to put
*
* If this is the last task in the namespace exiting, and
* it is dropping the refcount to 0, then it can race with
* a task in another ipc namespace but in a mounts namespace
* which has this ipcns's mqueuefs mounted, doing some action
* with one of the mqueuefs files. That can raise the refcount.
* So dropping the refcount, and raising the refcount when
* accessing it through the VFS, are protected with mq_lock.
*
* (Clearly, a task raising the refcount on its own ipc_ns
* needn't take mq_lock since it can't race with the last task
* in the ipcns exiting).
*/
void put_ipc_ns(struct ipc_namespace *ns)
{
if (refcount_dec_and_lock(&ns->ns.count, &mq_lock)) {
mq_clear_sbinfo(ns);
spin_unlock(&mq_lock);
if (llist_add(&ns->mnt_llist, &free_ipc_list))
schedule_work(&free_ipc_work);
}
}
free_ipc() 实现如下:
static LLIST_HEAD(free_ipc_list);
static void free_ipc(struct work_struct *unused)
{
struct llist_node *node = llist_del_all(&free_ipc_list);
struct ipc_namespace *n, *t;
llist_for_each_entry_safe(n, t, node, mnt_llist)
free_ipc_ns(n);
}
free_ipc_list 是一个无锁链表。llist_del_all() 会把链表头置空,然后 node 就是原来的链表头。llist_for_each_entry_safe() 会遍历链表,由 free_ipc_ns() 实际处理对应的 IPC namespace。
static void free_ipc_ns(struct ipc_namespace *ns)
{
/* mq_put_mnt() waits for a grace period as kern_unmount()
* uses synchronize_rcu().
*/
mq_put_mnt(ns);
sem_exit_ns(ns);
msg_exit_ns(ns);
shm_exit_ns(ns);
dec_ipc_namespaces(ns->ucounts);
put_user_ns(ns->user_ns);
ns_free_inum(&ns->ns);
kfree(ns);
}
这个 commit 处理部分与 mq_put_mnt() 这一部分有关,之前其调用:
// ipc/mqueue.c
void mq_put_mnt(struct ipc_namespace *ns)
{
kern_unmount(ns->mq_mnt);
}
// fs/namespace.c
void kern_unmount(struct vfsmount *mnt)
{
/* release long term mount so mount point can be released */
if (!IS_ERR_OR_NULL(mnt)) {
real_mount(mnt)->mnt_ns = NULL;
synchronize_rcu(); /* yecchhh... */
mntput(mnt);
}
}
EXPORT_SYMBOL(kern_unmount);
因此可以发现,这里每个 IPC namespace 都需要:
- 置空 mnt_ns;
- 等待 RCU grace period;
- mntput。
这个 commit 做的事情就是不要 kern_unmount(),而是在 free_ipc() 里面先一次性全部置空 mnt_ns,然后只需要等待一次 RCU grace period,最后再过一遍 free_ipc_ns()。free_ipc_ns() 内部调用也从 mq_put_mnt() 改成直接 mntput()。
听起来是个很棒的性能优化,但是这和我们的问题有什么关系呢?
free_ipc() 的性能提升 benchmark
先让我们看看这个 commit 给 free_ipc() 带来了什么性能提升吧。幸运的是,著名的系统性能分析专家 Brendan Gregg 写过一个分析 workqueue 中任务执行时间的 bpftrace 脚本,因此不用麻烦我去翻 bpftrace 的文档了。
在 5.15 与 6.3 上运行,free_ipc() 结果如下:
# 5.15
@us[free_ipc]:
[32K, 64K) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[64K, 128K) 0 | |
[128K, 256K) 0 | |
[256K, 512K) 0 | |
[512K, 1M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[1M, 2M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[2M, 4M) 0 | |
[4M, 8M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8M, 16M) 2 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16M, 32M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32M, 64M) 0 | |
[64M, 128M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[128M, 256M) 0 | |
[256M, 512M) 1 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
# 6.3.0
@us[free_ipc]:
[8K, 16K) 2 | |
[16K, 32K) 115 |@ |
[32K, 64K) 5109 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[64K, 128K) 1209 |@@@@@@@@@@@@ |
[128K, 256K) 1 | |
可以发现,5.15 上 free_ipc() 调用虽然不多,但是令人震惊地缓慢,最慢的竟然需要 256 到 512 秒才能执行完成(内核代码对放置在默认 system_wq 队列的要求是 “There are users which expect relatively short queue flush time. Don’t queue works which can run for too long.”)!6.3.0 上的就正常多了。除此之外,css_release_work_fn(), css_killed_work_fn(), cgroup_bpf_release() 这几个和 cgroup 有关的函数也出现了少量执行超过 1s 的任务(css = cgroup subsystem state)。
至少这说明了在大批量评测的场合,修复之前的 free_ipc() 本身确实存在一些性能问题(考虑到有大量创建了自己的 IPC namespace 的 runguard 进程不停被创建销毁)。But then? 这个工作队列照理是异步执行,为什么会影响到 runguard 子进程的 cgroup 呢?
Poor man’s stack profiler
对 runguard 分析的一个难点是,它是每次评测都要运行的,但是它的执行由 judgedaemon 这个 PHP 程序决定,评测本身又不长,不太容易 attach。@iBug 帮我写了个简单的 shell:
for pid in $(ps aux | awk '$8 == "D" && $11 = "/home/taoky/domjudge/judgehost/bin/runguard" { print $2 }'); do echo -e "\nStack for $pid"; cat /proc/$pid/stack; done
然后微调一下,每两秒输出到文件:
watch -n 2 -d 'DATE=$(date +%s); for pid in $(ps aux | awk '\''$8 == "D" && $11 = "/home/taoky/domjudge/judgehost/bin/runguard" { print $2 }'\''); do echo -e "\nStack for $pid" >> stack/$DATE; sudo cat /proc/$pid/stack >> stack/$DATE; done'
然后就能够看到 D 住的 runguard 到底卡哪里了,虽然不太完美,但是够用了。
拿到有问题和没问题的 stacks 信息,做一下简单的统计:
# 修复前的最后一个 commit 的内核
~/t/d/stack_lastbug> rg cgroup | wc
1781 3562 83949
~/t/d/stack_lastbug> rg free_ipc | wc
522 1044 19314
~/t/d/stack_lastbug> rg css | wc
1207 2414 56696
~/t/d/stack_lastbug> rg openat | wc
1113 2226 47827
~/t/d/stack_lastbug> rg rmdir | wc
553 1106 22354
# 修复后的第一个 commit 的内核
~/t/d/stack-firstfix> rg cgroup | wc
3 6 137
~/t/d/stack-firstfix> rg free_ipc | wc
165 330 6105
~/t/d/stack-firstfix> rg css | wc
1 2 46
~/t/d/stack-firstfix> rg openat | wc
0 0 0
~/t/d/stack-firstfix> rg rmdir | wc
0 0 0
似乎还真有点关系。肉眼翻了一些输出,发现有另一个单词出现很频繁:
~/t/d/stack_lastbug> rg shrinker | wc
451 902 21106
~/t/d/stack-firstfix> rg shrinker | wc
0 0 0
相关的函数包括 prealloc_shrinker(), reparent_shrinker_deferred(), unregister_shrinker()。第一、三个在 IPC namespace 创建/销毁的时候出现,第二个会被 css_killed_work_fn() 调用。看一下代码吧!
int prealloc_shrinker(struct shrinker *shrinker)
{
unsigned int size;
int err;
if (shrinker->flags & SHRINKER_MEMCG_AWARE) {
err = prealloc_memcg_shrinker(shrinker);
if (err != -ENOSYS)
return err;
shrinker->flags &= ~SHRINKER_MEMCG_AWARE;
}
size = sizeof(*shrinker->nr_deferred);
if (shrinker->flags & SHRINKER_NUMA_AWARE)
size *= nr_node_ids;
shrinker->nr_deferred = kzalloc(size, GFP_KERNEL);
if (!shrinker->nr_deferred)
return -ENOMEM;
return 0;
}
void reparent_shrinker_deferred(struct mem_cgroup *memcg)
{
int i, nid;
long nr;
struct mem_cgroup *parent;
struct shrinker_info *child_info, *parent_info;
parent = parent_mem_cgroup(memcg);
if (!parent)
parent = root_mem_cgroup;
/* Prevent from concurrent shrinker_info expand */
down_read(&shrinker_rwsem);
for_each_node(nid) {
child_info = shrinker_info_protected(memcg, nid);
parent_info = shrinker_info_protected(parent, nid);
for (i = 0; i < shrinker_nr_max; i++) {
nr = atomic_long_read(&child_info->nr_deferred[i]);
atomic_long_add(nr, &parent_info->nr_deferred[i]);
}
}
up_read(&shrinker_rwsem);
}
void unregister_shrinker(struct shrinker *shrinker)
{
if (!(shrinker->flags & SHRINKER_REGISTERED))
return;
down_write(&shrinker_rwsem);
list_del(&shrinker->list);
shrinker->flags &= ~SHRINKER_REGISTERED;
if (shrinker->flags & SHRINKER_MEMCG_AWARE)
unregister_memcg_shrinker(shrinker);
up_write(&shrinker_rwsem);
kfree(shrinker->nr_deferred);
shrinker->nr_deferred = NULL;
}
EXPORT_SYMBOL(unregister_shrinker);
有一些端倪:找到了一个全局的读写锁(信号量)shrinker_rwsem。而 prealloc_shrinker() 调用的 prealloc_memcg_shrinker() 也用到了这个信号量:
static int prealloc_memcg_shrinker(struct shrinker *shrinker)
{
int id, ret = -ENOMEM;
if (mem_cgroup_disabled())
return -ENOSYS;
down_write(&shrinker_rwsem);
/* This may call shrinker, so it must use down_read_trylock() */
id = idr_alloc(&shrinker_idr, shrinker, 0, 0, GFP_KERNEL);
if (id < 0)
goto unlock;
if (id >= shrinker_nr_max) {
if (expand_shrinker_info(id)) {
idr_remove(&shrinker_idr, id);
goto unlock;
}
}
shrinker->id = id;
ret = 0;
unlock:
up_write(&shrinker_rwsem);
return ret;
}
搞不好时间都花在了锁上头,而且这个锁还是全局的。
在 cgroup 这里,也有一些有趣的东西,不少 cgroup 函数都需要获取 cgroup_mutex,比如说上面我们提到的 css_killed_work_fn():
/*
* This is called when the refcnt of a css is confirmed to be killed.
* css_tryget_online() is now guaranteed to fail. Tell the subsystem to
* initiate destruction and put the css ref from kill_css().
*/
static void css_killed_work_fn(struct work_struct *work)
{
struct cgroup_subsys_state *css =
container_of(work, struct cgroup_subsys_state, destroy_work);
mutex_lock(&cgroup_mutex);
do {
offline_css(css);
css_put(css);
/* @css can't go away while we're holding cgroup_mutex */
css = css->parent;
} while (css && atomic_dec_and_test(&css->online_cnt));
mutex_unlock(&cgroup_mutex);
}
这把 mutex 锁同样也是全局的。难道是锁导致的问题?
Lock stat
好消息:Kernel 支持统计每个锁的信息,包括等待锁的时间、持有锁的时间等等;
坏消息:要重新编译内核。
不过反正我都编译了十几次了,再来几次也无妨。然后和上面一样,每两秒读一下 /proc/lock_stat 的内容记录下来。
选一个高峰期的统计数据:
class name con-bounces contentions waittime-min waittime-max waittime-total waittime-avg acq-bounces acquisitions holdtime-min holdtime-max holdtime-total holdtime-avg
shrinker_rwsem-W: 3995 5539 0.12 826880.50 474904067.23 85738.23 100759 156706 0.00 827284.22 73644524.74 469.95
shrinker_rwsem-R: 222 227 0.36 604864.05 47812995.44 210629.94 39633 42040 0.57 544.72 3316088.16 78.88
----------------
shrinker_rwsem 1753 [<00000000c82e9511>] __prealloc_shrinker+0x74/0x360
shrinker_rwsem 341 [<000000009fa4c964>] unregister_shrinker+0x20/0x90
shrinker_rwsem 3383 [<00000000c42b3549>] register_shrinker_prepared+0x1c/0x70
shrinker_rwsem 62 [<0000000032cb78dd>] alloc_shrinker_info+0x1a/0x110
----------------
shrinker_rwsem 3852 [<00000000c82e9511>] __prealloc_shrinker+0x74/0x360
shrinker_rwsem 1604 [<00000000fbba4669>] reparent_shrinker_deferred+0x28/0x100
shrinker_rwsem 239 [<0000000032cb78dd>] alloc_shrinker_info+0x1a/0x110
shrinker_rwsem 18 [<000000009fa4c964>] unregister_shrinker+0x20/0x90
cgroup_mutex: 346315 355424 0.40 1017647.63 40646408006.90 114360.34 922305 1130556 0.00 685445.13 2132487536.75 1886.23
------------
cgroup_mutex 116559 [<000000000a638515>] cgroup_kn_lock_live+0x4d/0x140
cgroup_mutex 29751 [<00000000c1655a73>] proc_cgroup_show+0x4a/0x2d0
cgroup_mutex 54064 [<00000000fe36961a>] css_release_work_fn+0x24/0x260
cgroup_mutex 98304 [<00000000f076cd76>] cgroup_bpf_release+0x4d/0x330
------------
cgroup_mutex 191675 [<000000000a638515>] cgroup_kn_lock_live+0x4d/0x140
cgroup_mutex 160964 [<00000000fa2cc618>] css_killed_work_fn+0x19/0x150
cgroup_mutex 2401 [<00000000fe36961a>] css_release_work_fn+0x24/0x260
cgroup_mutex 326 [<00000000c1655a73>] proc_cgroup_show+0x4a/0x2d0
得到:
-
shrinker_rwsem- 写锁最大等待时间 826880us,最大持有时间 827284us;
- 读锁最大等待时间 604864us,最大持有时间 545us;
-
cgroup_mutex- 最大等待时间 1017648us,最大持有时间 685445us。
因此可以确定是锁(特别是 shrinker_rwsem 写锁)导致的问题了。
Debugging with… printk() + ktime_get()?
用 BPF 应该可以实现任意内核代码的高效时间统计,但是因为调试符号打 deb 实在太慢了,所以我没打,然后就也不知道 kprobe 应该放哪里,所以最终还是采用了最原始的调试方案:printk(),然后用 ktime_get() 获取时间。可能有一些 overhead 吧——大概会有几 us?
mm/vmscan.c 中需要写锁的有这么几个函数:prealloc_memcg_shrinker(), alloc_shrinker_info(), free_prealloced_shrinker(), register_shrinker_prepared() 和 unregister_shrinker()。看一下 stack 记录里面的几位出场嘉宾:
> rg shrinker | cut --delimiter=" " -f2 | cut --delimiter="+" -f1 | sort | uniq -c
3 alloc_shrinker_info
183 __prealloc_shrinker
183 prealloc_shrinker
34 reparent_shrinker_deferred
48 unregister_shrinker
alloc_shrinker_info() 出镜率实在太低了,所以就先不管了。reparent_shrinker_deferred() 拿的是读锁,而 unregister_shrinker() 确实是写锁,但是观察实现发现唯一可能花一点点时间的是它调用的 unregister_memcg_shrinker():
static void unregister_memcg_shrinker(struct shrinker *shrinker)
{
int id = shrinker->id;
BUG_ON(id < 0);
lockdep_assert_held(&shrinker_rwsem);
idr_remove(&shrinker_idr, id);
}
但是 IDR 好歹是个 radix tree 变种,要是删个元素就要几百毫秒的话也实在说不过去(当然,我加过,然后发现它的执行时间根本不可能达到百毫秒的量级,以及高峰期 shrinker_idr 看起来数量级在上万左右)。
问题只可能在 prealloc_memcg_shrinker() 上面。IDR 分配和删除也不太可能占用那么多时间,因此给 expand_shrinker_info() 加了个 printk():
@@ -379,10 +385,14 @@ static int prealloc_memcg_shrinker(struct shrinker *shrinker)
goto unlock;
if (id >= shrinker_nr_max) {
+ ktime_t start, end;
+ start = ktime_get();
if (expand_shrinker_info(id)) {
idr_remove(&shrinker_idr, id);
goto unlock;
}
+ end = ktime_get();
+ printk(KERN_INFO "expand_shrinker_info taken %lld ns\n", ktime_to_ns(ktime_sub(end, start)));
}
shrinker->id = id;
ret = 0;
(goto unlock 在测试中没有出现,所以偷懒了)
然后编译,重启,交一堆评测,结束之后收 kern.log,确实有慢到离谱的:
Nov 29 18:35:12 cactus kernel: [ 1494.674610] expand_shrinker_info taken 476731026 ns
static int expand_shrinker_info(int new_id)
{
int ret = 0;
int new_nr_max = new_id + 1;
int map_size, defer_size = 0;
int old_map_size, old_defer_size = 0;
struct mem_cgroup *memcg;
if (!need_expand(new_nr_max))
goto out;
if (!root_mem_cgroup)
goto out;
lockdep_assert_held(&shrinker_rwsem);
map_size = shrinker_map_size(new_nr_max);
defer_size = shrinker_defer_size(new_nr_max);
old_map_size = shrinker_map_size(shrinker_nr_max);
old_defer_size = shrinker_defer_size(shrinker_nr_max);
memcg = mem_cgroup_iter(NULL, NULL, NULL);
do {
ret = expand_one_shrinker_info(memcg, map_size, defer_size,
old_map_size, old_defer_size);
if (ret) {
mem_cgroup_iter_break(NULL, memcg);
goto out;
}
} while ((memcg = mem_cgroup_iter(NULL, memcg, NULL)) != NULL);
out:
if (!ret)
shrinker_nr_max = new_nr_max;
return ret;
}
嫌疑最大的就是 do-while 了。如法炮制对每次迭代输出,然后写个脚本统计一下时间 (ns) 和前十名:
19520: 702339350, max: 3940353, cnt: 9026, avg: 77812.91269665411
18368: 639621126, max: 744031, cnt: 8916, avg: 71738.57402422611
20544: 635646321, max: 802928, cnt: 9128, avg: 69636.97644609991
20416: 631049831, max: 7987415, cnt: 9032, avg: 69868.22752435783
19328: 628072921, max: 11967237, cnt: 8870, avg: 70808.67204058624
18496: 614502461, max: 839398, cnt: 8792, avg: 69893.36453594177
19904: 611960697, max: 7229538, cnt: 9041, avg: 67687.2798363013
18112: 608502773, max: 1009415, cnt: 8535, avg: 71294.99390743996
19456: 599951989, max: 12143250, cnt: 8965, avg: 66921.582710541
19264: 592053029, max: 12948429, cnt: 8803, avg: 67255.8251732364
对比 commit 之后的内核的数据:
64: 206006, max: 9337, cnt: 113, avg: 1823.0619469026549
(只在最开始有一次,后面就没有再 expand 过了)
可以发现:
- 循环次数多了一个数量级(因为 cgroup 被锁卡着很难清理);
- 每次循环时间平均也多了一个数量级(可能是高负载导致的)。
推论
合计用了两天半时间,不停看代码、测试,最后我的推论是:
- 大量的评测导致大量的 runguard 进程被创建和销毁;
- 销毁的 runguard 进程的 IPC namespace 也要销毁,但是因为内核的问题,每一个都要全局同步 RCU,销毁速度非常慢;每个销毁都需要获取
shrinker_rwsem写锁 (unregister_shrinker); - runguard 进程的 cgroup 也需要清理,对应的 cgroup subsystem state 的销毁工作的一部分给了
css_killed_work_fn(),它同时需要cgroup_mutex锁以及shrinker_rwsem读锁 (reparent_shrinker_deferred); - 因为销毁很慢,因此 IDR 里面分不出老的不再使用的 ID,只能分出新的,因此
expand_shrinker_info()会被频繁执行,它的执行速度和当前拥有的(还没有销毁的)memory cgroup 数量正相关; - 随着时间推移,负载打满,
expand_shrinker_info()的执行时间会越来越长(在有很多核心的服务器上可能更显著,因为expand_one_shrinker_info()的执行时间和系统核心数量是线性关系),最终导致shrinker_rwsem写锁释放缓慢,而cgroup_mutex也因此释放缓慢(拿不到shrinker_rwsem的读锁),memory cgroup 也随之增多(但是不会无限增长,因为创建也需要cgroup_mutex),推动了这个恶性循环;- 现场的配置可能也有一些问题:最开始开启的评测 instance 是 0 到 20,但是 NUMA 的情况下绝大部分的评测 worker 都会挤在一个 CPU 上面。但是即使 NUMA 分配正确,也最多只会推迟问题,在高负载 45min 以上的情况下很可能还会发生。
- cgroup 操作迟迟无法结束,如果发生在 Wall time 记时外,那么不会在 DOMjudge 页面上表现出来,但是评测时间会显著增长;如果发生在 Wall time 记时内,表现即为 Wall time » CPU time。如果设置的 Wall time 上限比较小,那么就会直接 TLE,即使上限比较大,也会导致评测时间显著增长。
- 进入到了无法挽回的局面(即使重启机器,在这段时间的评测堆积也肯定会再次导致这个问题)。
- 现场唯一能做的事情就是忍受慢速评测,提高 Wall time 限制(或者我穿越回当天,说服所有人升级内核或者关闭 IPC 隔离)。当场发现问题根源是不可能的(加服务器也不可能,因为需要保证型号一致,否则题目测试点的时间限制就不准确了)。
- 即使现场发现了 cgroup 可能有问题,因为需要 cgroup 限制内存使用,所以从 runguard 中去掉 cgroup 的使用也是无法接受的。
- 如果这么看,这个 commit 可能没有解决本质问题,在这个问题上卡顿的可能性仍然存在(只是概率低得多、过程更加缓慢因此可以接受了而已)。
- 我自己测试是偶尔还会出现一批进程 D 的情况,但是出现频率很低,跑比较长的时候 load 也只是略高于 worker 的数量。
- 以及,其他的评测系统,只要每个评测点都创建一个新环境,并且用到 cgroup 和 unshare IPC 的(包括容器),都可能有这个问题。
- 如何彻底在内核中修复这个问题?我不知道。
- 字节跳动的 Qi Zheng 在今年初 [PATCH v2 0/7] make slab shrink lockless 中提及了
expand_shrinker_info()可能导致shrinker_rwsem写锁被占用时间太长的问题,但是对应的 patch 合入之后因为新的性能问题又被 revert,之后的新补丁从我阅读代码来看,似乎锁仍然存在,上面提到的两个地方仍然有可能要抢锁(shrinker_rwsem变成了shrinker_mutex,因为补丁修改后reparent_shrinker_deferred()是唯一需要读锁的地方,而它又已知有cgroup_mutex,所以变成了shrinker_mutex)。
- 字节跳动的 Qi Zheng 在今年初 [PATCH v2 0/7] make slab shrink lockless 中提及了
如何测试自己的部署?
我修改出了一个独立的版本,不需要部署 DOMjudge web 即可测试:https://github.com/taoky/judgescale。同时它会将 Wall - CPU 的时间差和总测评时间记录,方便在 DOMjudge 中预估、设置合理的 Wall time limit。
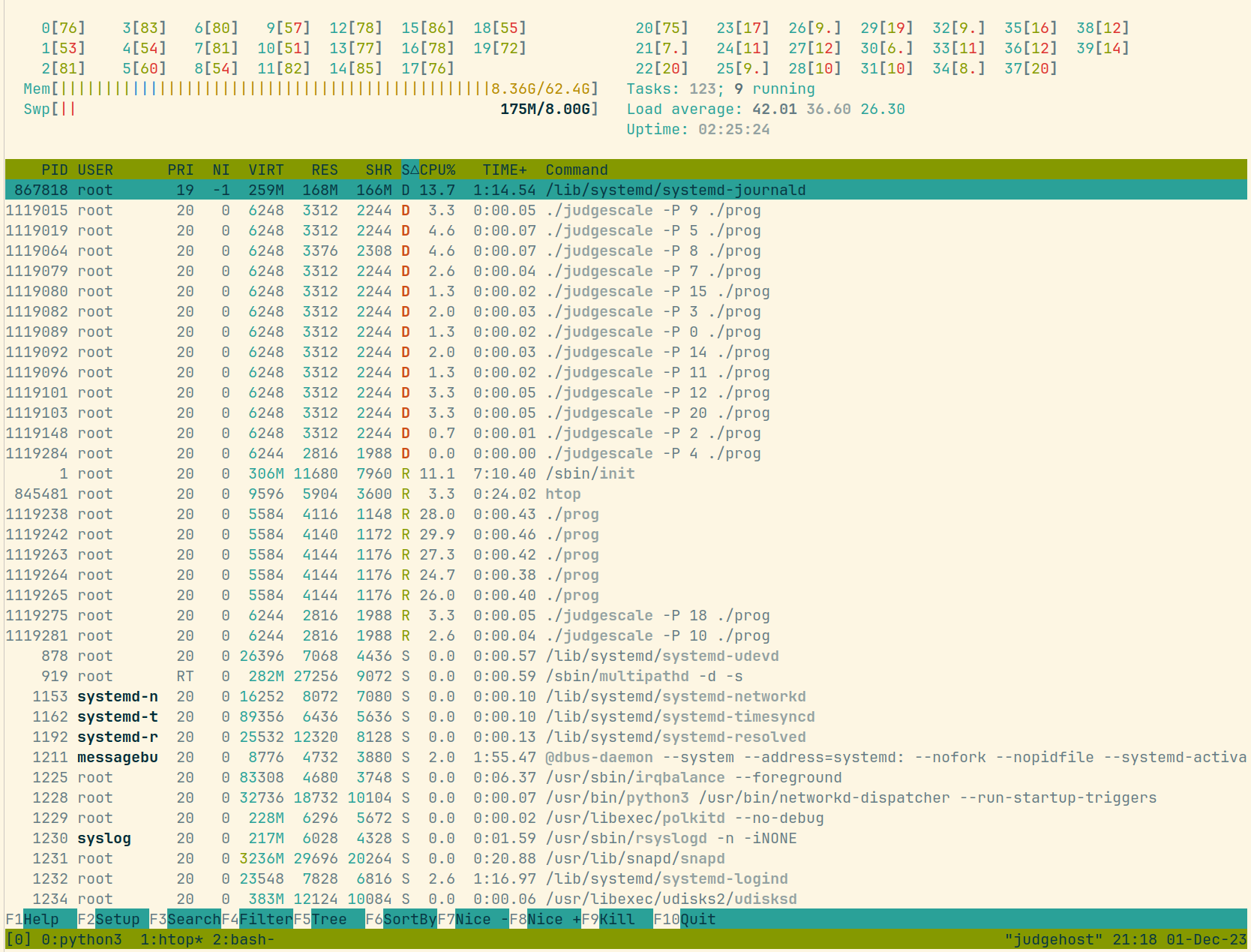
在本次的评测机上测试不间断同时进行 21 个评测,在全速评测不到 25 分钟内(从 uptime 2h 开始测试),就出现了此次问题的症状(评测监管进程 D,load 大于等于开启任务数量的两倍):
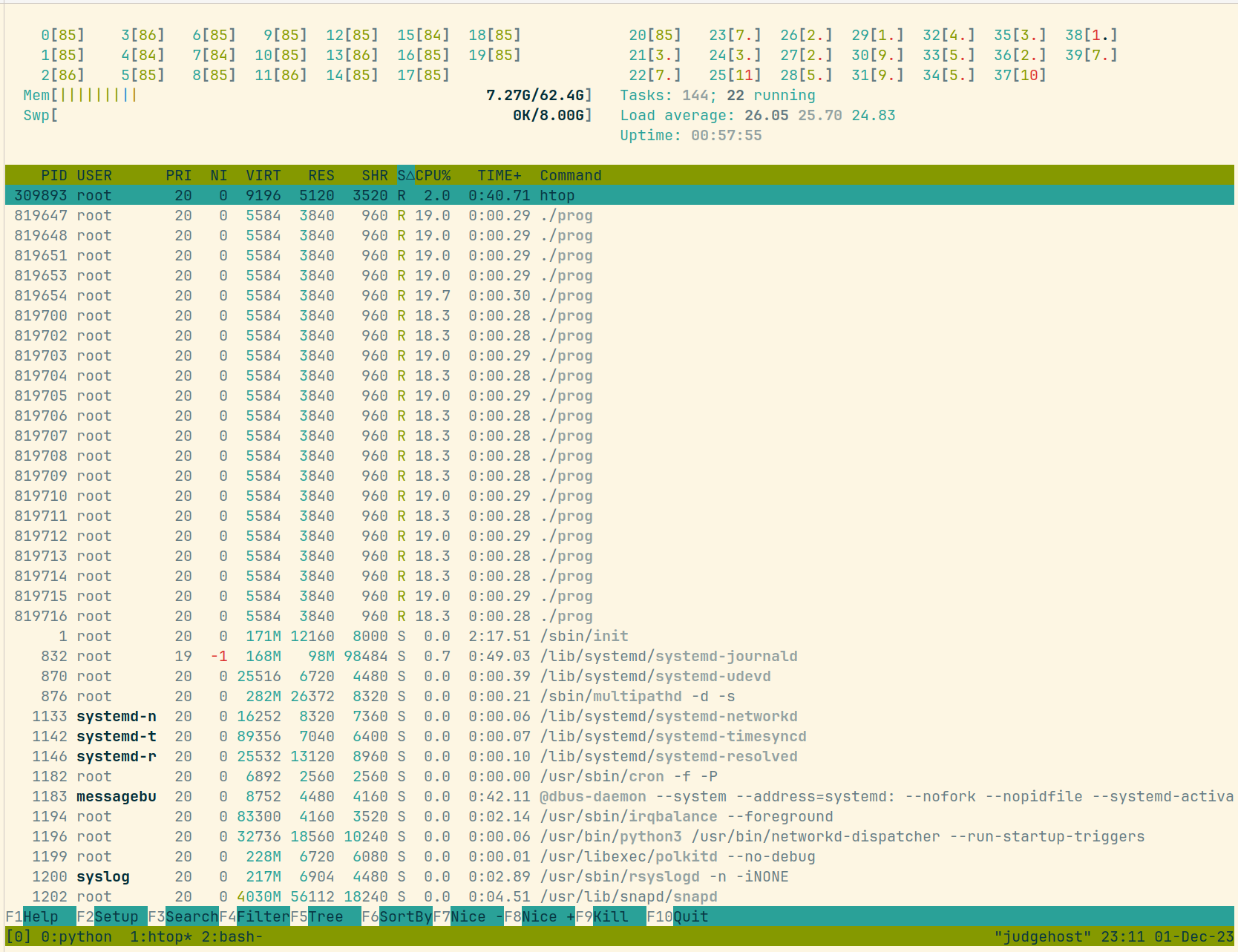
在安装 Linux 6.3.0 内核包后,相同条件运行接近 1h,1 分钟最高 load 在 30:
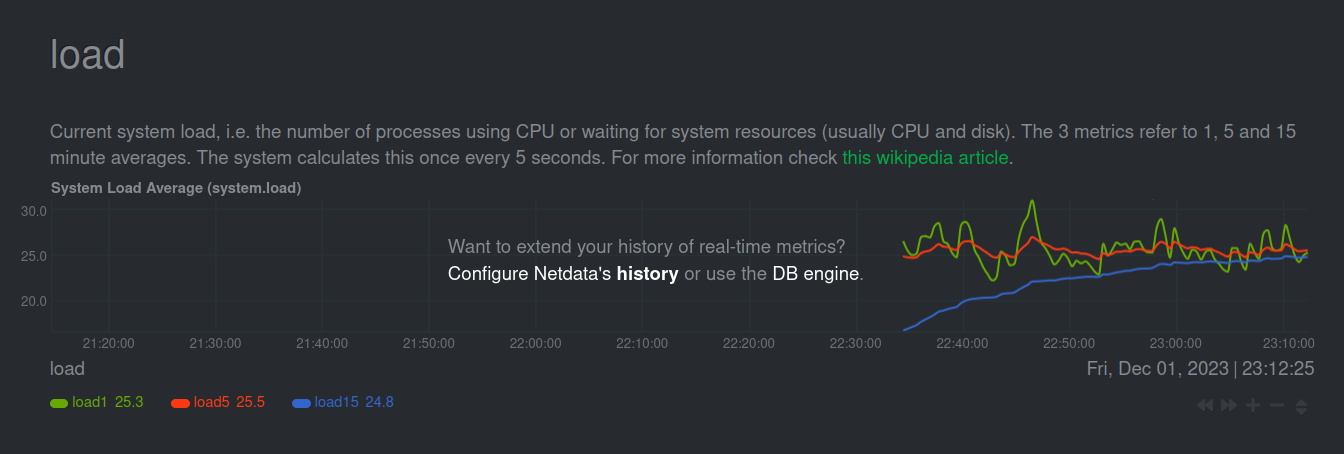
(在压测中途安装了 netdata):
此外,测试时发现该服务器的内核(5.15 和 6.3)仅会在系统负载高的时候不停输出 “enoX speed is unknown, defaulting to 1000” 的信息(所以赛前也没人发现网卡的问题),从源代码看相关信息是 ib_core 输出的(i40e -> irdma -> ib_core),但是调试条件有限,因此其具体原因仍然不明。手动禁用 irdma 重启后就不会再出现这个问题了。处理后再测试了两个小时,Linux 6.3.0 内核下 21 个评测 worker load 稳定在 20 到 25,Wall - CPU 时间的值不超过 0.25s,考虑到在不超过 Wall time limit 情况下判断 TLE 是按照 CPU 时间为标准的,内核更新到 6.3 或以上之后应当就足以应对比赛环境了。
Update 1 (2023/12/05): 如果只修改 runguard,让父子进程同步保证 setrestrictions() 不计入 Wall time 能解决问题吗?修改了一下 runguard 代码之后测试,发现问题仍然可能存在:
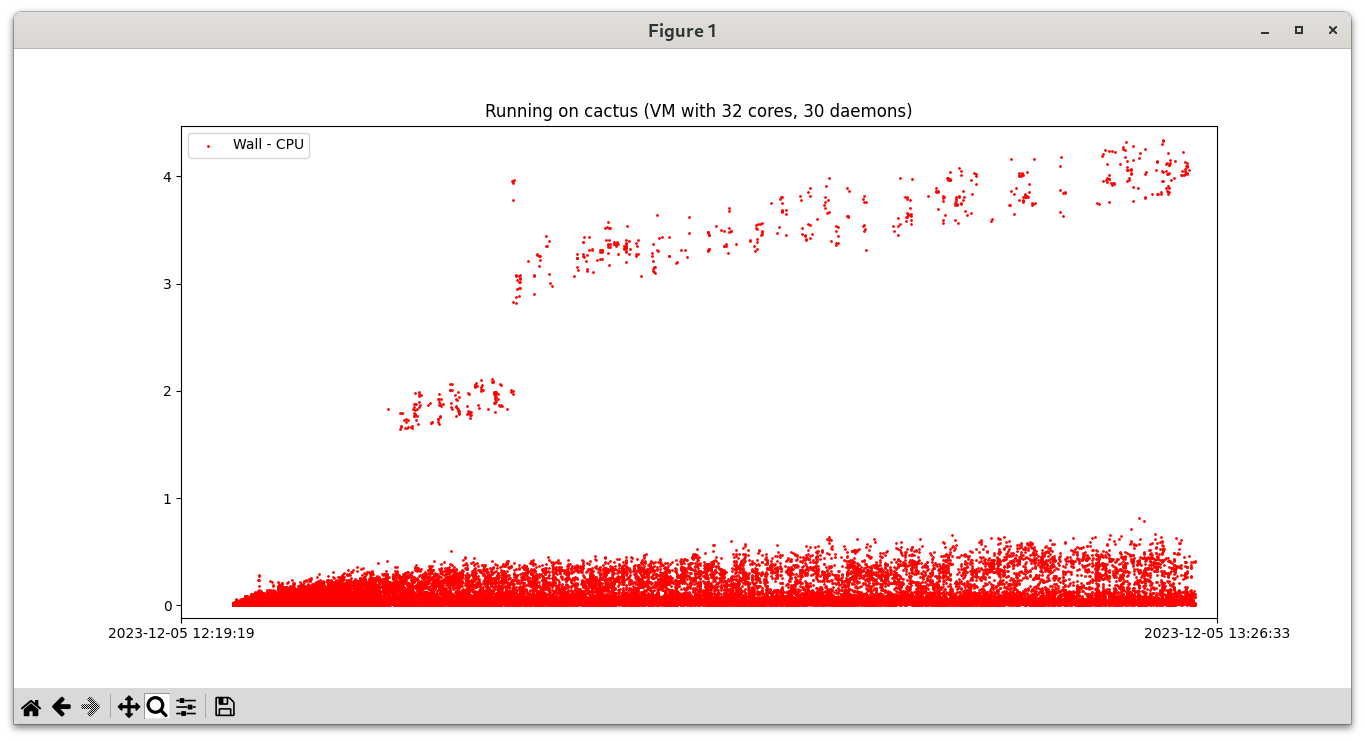
从上面字节最开始的 patch 的内容来看(因为最近没有足够的精力,我没有去抓现场,因此这一段的内容都是推测),问题应该出在缺页处理(handle_mm_fault)的时候需要更新内存 cgroup 的统计数据(可以看我在一月份的 post,恰巧提到了这个事情),而更新数据需要 shrink_slab,从而需要 shrinker_rwsem 的读锁导致的。所以可能只能靠大版本更新内核来缓解问题(或者想办法把上面的 commit backport 到老的内核上)。
这里感谢坏人 (@shankerwangmiao) 对此的提问与建议。
结论
Q: Do you judgehosts scale?
A: With
cgroup_mutexandshrinker_rwsem, NO (in Linux < 6.3).
Comments